
私はいままでの経験でSEOに取り組んだことがない。一から調べてできることを実装した。 読者としてはNext.jsを使っていて、自前でSEOを始めようとする人が対象になる。 それほど、高い技術は必要ないので、開発者でなくても十分できるだろう。
前提としてのこのサイト構成
このblogはwordpressなどは使っていない。Next.jsをStatic ExportsにしてFirebase HostingにHostingしている。ブログの記事の管理にmicroCMSを使うことにした。 知らない人のために記載する。
-
SEOの基本概念
Next.jsのStatic Exportsは、各ページをビルド時にHTMLファイルとして生成するため、サーバー側でのレンダリング処理が不要になり、CDNを利用した高速配信が可能だ。 -
Firebase Hosting:
グローバル CDN(コンテンツ配信ネットワーク)にデプロイするサービス。 -
microCMS:
microCMSは、日本製のヘッドレスCMSで、シンプルなAPIを通してコンテンツを管理・配信できる。ドキュメントが充実しており、初心者でも扱いやすい点が特徴。
Firebase Hostingは高速な配信、microCMSはコンテンツ管理といった役割分担だ。このような構成したのは、あとで動的なアプリなども作りたいと考えたので、現時点では以下の構成にしている。
output: 'export'を設定するとStatic Exportsになる。
// next.config.ts
import type { NextConfig } from 'next';
const nextConfig: NextConfig = {
output: 'export',
...
};
export default nextConfig;
SEOについて自分の言葉で表現してみる
SEOはSearch Engine Optimizationの略だ。日本語では検索エンジン最適化と訳される。つまり、ウェブサイトやコンテンツを検索エンジンにとって「理解しやすく」、かつ「魅力的」にするための最適化手法だ。結果的に広告費をかけずに、自然検索からのアクセスを増やす。検索ユーザの意図(インテント)に沿った情報を提供することで、ユーザ満足度と信頼性を高めることができる。
検索は次のように行われる
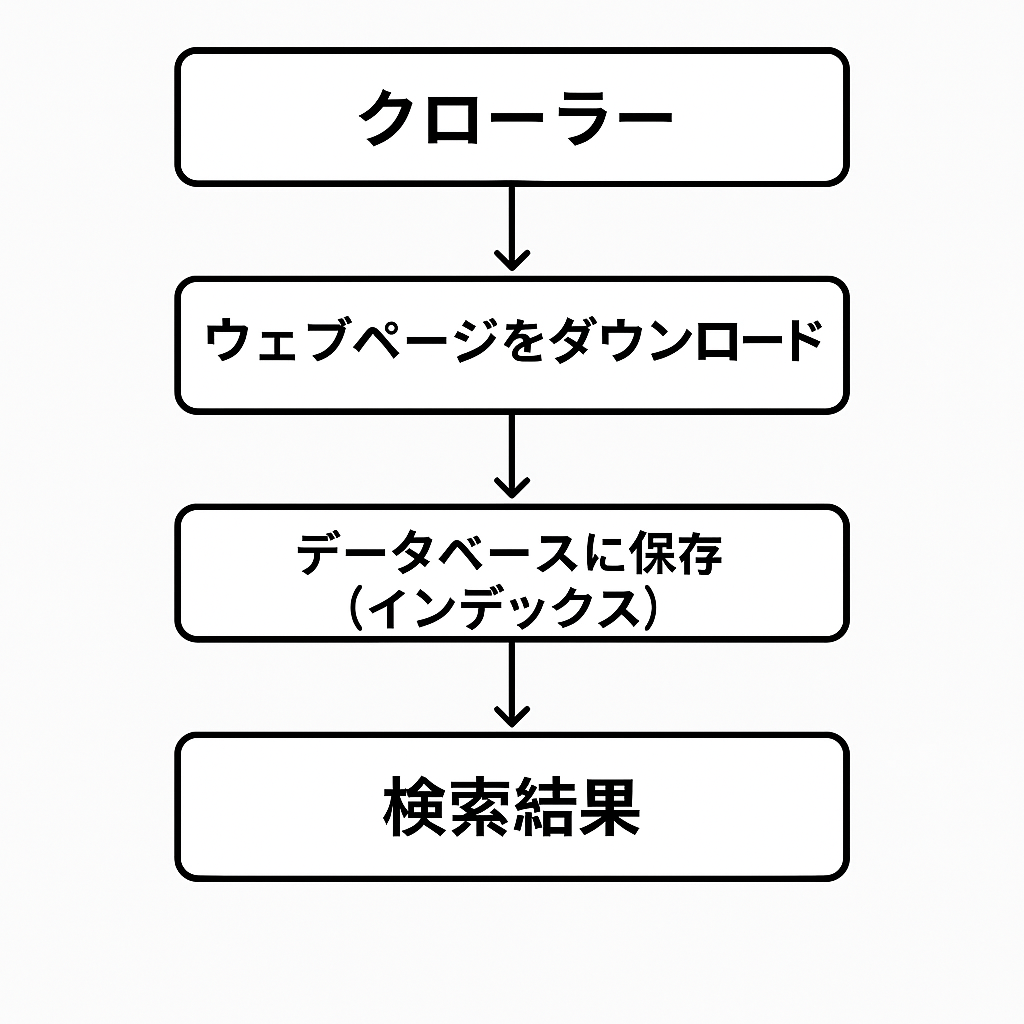
- クローラーというプログラムでウェブ上を探索し、ブラウザと同じようにページをダウンロードする。
- 見つけたページを解析してデータベースに保存する。このデータベースがインデックスと呼ばれている。
その後、ユーザが検索すると、検索語句に関する情報が返される。これはインデックスが利用されるのだろう。もしかしたらベクトルになっているのかもしれない。
取り組むトピック
クロールとインデックス登録に関するトピックの概要と検索の見え方に関するトピックを参照した。以下を実施することにした。効果が乏しければ、トピックを追加したい。
| No | topic | 概要 |
|---|---|---|
| 1 | robots.txt | クローラーにどのページにアクセスしていいか悪いかを知らせるもの。 |
| 2 | サイトマップ | サイトマップ上の新しいページや更新されたページについて、Googleに通知できる |
| 3 | ページとコンテンツのメタデータ | ページについて主に表示に関する情報をクローラーに伝える |
| 4 | 構造化データ | ページのコンテンツをGoogleに認識させる。検索結果の見え方に影響する。 |
robots.txtをつくる
概要に記載したとおり、robots.txtはサイトのどのURLにアクセスしてよいかクローラーに伝えるものだ。書き方はGoogle検索セントラルに記載がある。私が注意したことを抜粋する。
- ファイル名は「robots.txt」にする。各サイトにはひとつのみ作成できる。
- 適用するサイトのルートに配置する必要がある。https://mydomain.com/robots.txtのようにする。
- robots.txtは1つ以上のルールのセットで構成される。ユーザーエージェント毎に定義できるようだ。
- クローラーは上から順に処理する
robots.txtのルール
| ルールのパラメータ | 説明 |
|---|---|
| user-agent | 必須。*は全て。ただし、AdsBotは明示的に指定する必要がある。AdsBotは広告の品質を確認するクローラー。 |
| allow or disallow | allow または disallowのいずれかが少なくとも一つ必要。先頭は/文字にする必要があり、クロールを許可または禁止するのに使う |
| sitemap | 省略可。ファイルごとにゼロ個以上。対象サイトのサイトマップがある場所の完全修飾URL |
Next.jsで実装
Next.jsのドキュメントを参照し 広告を出したときのためにAdsBot-Googleもいれた。 sitemapはまだ作っていないが作る予定なのでコメントアウトしている。
//app/robots.ts
import type { MetadataRoute } from 'next';
export default function robots(): MetadataRoute.Robots {
return {
rules: [
{
userAgent: '*',
allow: '/',
},
{
userAgent: 'AdsBot-Google',
allow: '/',
},
],
// sitemap: 'https://mokay.tech/sitemap.xml',
};
}
Next.jsのbuildが失敗したので修正
以下のエラーが発生した
Error: export const dynamic = "force-static"/export const revalidate not configured on route "/robots.txt" with "output: export".
原因:
Static ExportsではISR(Incremental Static Regeneration)がサポートされていません。ISRはビルド後もページを再生成して最新状態を保つ仕組みですが、静的HTMLとして出力するStatic Exportsと性質が異なるため、今回のようなrobots.txtには適用できません。
解決策:
robots.txtは更新される必要がないため、ISRを無効にして完全な静的コンテンツとして扱うように設定する。具体的にはexport const dynamic = 'force-static'を追加した。これでbuildができた。
// app/robots.ts
import type { MetadataRoute } from 'next';
export const dynamic = 'force-static';
export default function robots(): MetadataRoute.Robots {
return {
rules: [
{
userAgent: '*',
allow: '/',
},
{
userAgent: 'AdsBot-Google',
allow: '/',
},
],
// sitemap: 'https://mokay.tech/sitemap.xml',
};
}
サイトマップも作成
サイトマップはサイト上のページについての情報を検索エンジンに伝えるファイルだ。サイトのサイズが小さい場合や内部リンクが網羅している場合は必要がない可能性がある。必要ないかもしれないがrobots.txtで指定するので、作ってみることにした。
簡単にできそうなnext-sitemapを使うことにした
サイトマップについてはNext.jsにも用意がされていた。このドキュメントである。しかし、簡単にできそうだったのでnext-sitemapに書かれているとおりにした。
まずはインストールする。
npm install --save-dev next-sitemap
設定ファイルを追加する。generateRobotsTxtはrobots.txtを作成するオプション。すでに作っているのでfalseにした。
// next-sitemap.config.js
module.exports = {
siteUrl: 'https://mokay.tech',
generateRobotsTxt: false,
};
scriptsに追加した。
// package.json
{
...
"scripts": {
"postbuild": "next-sitemap"
},
...
}
実行した
npm run postbuild
実行するとsitemap.xml,sitemap-0.xmlが出力された。sitemap.xmlはサイトマップインデックスファイルというもので、サイトマップがサイズ制限以下になるように分割するためにある。
robots.tsも合わせて修正した。sitemapのコメントアウトを外したのだ。これでsitemapもクロールされるようになるはずだ。
// app/robots.ts
import type { MetadataRoute } from 'next';
export const dynamic = 'force-static';
export default function robots(): MetadataRoute.Robots {
return {
rules: [
{
userAgent: '*',
allow: '/',
},
{
userAgent: 'AdsBot-Google',
allow: '/',
},
],
sitemap: 'https://mokay.tech/sitemap.xml',
};
}
ページとコンテンツのメタデータもいれる
メタデータは主にmetaタグでいれる。metaタグはHTMLのタグだ。<head>セクションに入れる。OGP(Open Graph Protocol)もここに入れられる。OGPはXやFacebookなどのSNSに補足情報を表示するための仕組みだ。
Next.jsではgenerateMetadataでいれられる。 私はmicroCMSのAPIからblogのデータを取得し、page.tsxに流し込み、ページを作っている。そこに追加した。page.tsxのPropsと型が一致してないければならない。
generateMetadataのメソッドに各metaタグに対応する設定をいれるようにしている。
// src\app\blog\[id]\page.tsx
// 記事詳細ページの生成
export default async function BlogArticle({ params }: { params: Promise<{ id: string }> }) {
const { id } = await params; // IDを取得
const blog = await getBlog(id);
const formattedDate = dayjs(blog.publishedAt).format('YY.MM.DD');
return (
<>
<Header className={appStyle.backgroundHero} />
<main className={`${appStyle.partsGrid} ${styles.blogArticle}`}>
<section
className={`${styles.blogArticleHeader} ${appStyle.grid12}`}
style={{
backgroundImage: `url(${blog.eyecatch.url})`,
backgroundSize: 'cover',
backgroundPosition: 'center bottom',
}}
>
<h1>{blog.title}</h1> {/* タイトルを表示 */}
<time>{formattedDate}</time> {/* 日付を表示 */}
</section>
<ul className={styles.tag}>
{blog.tags &&
blog.tags.map((tag) => (
<Link key={tag.id} href={`/blog?tag=${tag.name}`}>
<TagButton key={tag.id} name={tag.name} />
</Link>
))}
</ul>
<BlogArticleContent content={blog.content} />
</main>
<Footer />
</>
);
}
export async function generateStaticParams() {
const blogIds = await getAllBlogIds('blog');
return blogIds.map((contentId) => ({
id: contentId, // 各記事のIDをパラメータとして返す
}));
}
// DBの値を使ってメタデータを動的に生成する
export async function generateMetadata({ params }: { params: Promise<{ id: string }> }) {
const { id } = await params;
const blog = await getBlog(id);
const plainText = blog.content.replace(/<[^>]*>/g, '');
return {
title: blog.title,
description: plainText.slice(0, 150), // 例:内容の先頭150文字を抜粋
openGraph: {
title: blog.title,
description: plainText.slice(0, 150),
url: `https://${process.env.NEXT_PUBLIC_MY_DOMAIN}/blog/${blog.id}`,
images: [
{
url: blog.eyecatch.url,
width: 1200,
height: 630,
alt: blog.title,
},
],
},
twitter: {
card: 'summary_large_image',
},
alternates: {
canonical: `https://${process.env.NEXT_PUBLIC_MY_DOMAIN}/blog/${blog.id}`,
},
};
}
構造化データもいれる
構造化データも検索エンジンに情報を伝えるが、表示に関してではなく、意味や属性を伝えるようになっている。
形式としてはJSON-LDがGoogleでは推奨されているので、それで実装しよう。 守るべき一般的なガイドラインがある。技術的なチェックはリッチリザルトに対応しているかのチェックでほとんど検出できる。
品質については不正をしなければいいだろう。
@contextや@typeについての説明がGoogleの方でなかったので探した。 これらはW3Cで定義されているようだ。
Blogの記事なのでArticleオブジェクトのプロパティを参考にした。
jsonLdにプロパティの設定をいれて、最終的にscriptタグとして出力されるように修正している
// src\app\blog\[id]\page.tsx
// 記事詳細ページの生成
export default async function BlogArticle({ params }: { params: Promise<{ id: string }> }) {
const { id } = await params; // IDを取得
const blog = await getBlog(id);
const formattedDate = dayjs(blog.publishedAt).format('YY.MM.DD');
const jsonLd = {
'@context': 'https://schema.org',
'@type': 'BlogPosting',
author: [
{ '@type': 'Organization', name: 'MOKAY TECH', url: `${process.env.NEXT_PUBLIC_MY_DOMAIN}/` },
],
datePublished: blog.publishedAt,
dateModified: blog.revisedAt,
headline: blog.title,
image: [
`${blog.eyecatch.url}?ar=1:1&fit=crop`,
`${blog.eyecatch.url}?ar=4:3&fit=crop`,
`${blog.eyecatch.url}?ar=16:9&fit=crop`,
],
};
return (
<>
<script
type="application/ld+json"
dangerouslySetInnerHTML={{ __html: JSON.stringify(jsonLd) }}
/>
);
}
export async function generateStaticParams() {
const blogIds = await getAllBlogIds('blog');
return blogIds.map((contentId) => ({
id: contentId, // 各記事のIDをパラメータとして返す
}));
}
// DBの値を使ってメタデータを動的に生成する
export async function generateMetadata({ params }: { params: Promise<{ id: string }> }) {
const { id } = await params;
const blog = await getBlog(id);
const plainText = blog.content.replace(/<[^>]*>/g, '');
return {
title: blog.title,
description: plainText.slice(0, 150), // 例:内容の先頭150文字を抜粋
openGraph: {
title: blog.title,
description: plainText.slice(0, 150),
url: `https://${process.env.NEXT_PUBLIC_MY_DOMAIN}/blog/${blog.id}`,
images: [
{
url: blog.eyecatch.url,
width: 1200,
height: 630,
alt: blog.title,
},
],
},
twitter: {
card: 'summary_large_image',
},
alternates: {
canonical: `https://${process.env.NEXT_PUBLIC_MY_DOMAIN}/blog/${blog.id}`,
},
};
}
まとめ
本記事では、Next.jsとmicroCMSを活用したSEO対策の基本的な実装方法について解説しました。
主なポイントは以下の通りです。
-
SEOの基本概念
SEOとは検索エンジン最適化のことで、コンテンツやサイト構造を改善し、検索結果での表示順位向上を目指します。オンページ、オフページ、技術的SEOの各側面から、ユーザの意図に沿った情報提供が重要です。 -
Next.jsを利用した静的サイト生成
Next.jsのStatic Exportsを用いることで、高速かつ柔軟なサイト運用が可能になりました。Firebase HostingやmicroCMSとの組み合わせにより、将来的なアプリ開発への展開も視野に入れた設計が実現されています。 -
robots.txtとサイトマップの実装
クローラーに対するアクセスルールをrobots.txtで設定し、サイトマップにより新規ページや更新情報をGoogleに伝える仕組みを構築。AdsBot-Googleにも対応することで、広告掲載時の品質チェックにも備えています。 -
メタデータと構造化データの活用
metaタグやOpen Graph、JSON-LDを用いることで、検索エンジンに対してページの内容や構造を正確に伝え、リッチリザルト表示を狙う取り組みを実施しました。
これらの対策を基盤として、今後は効果の検証とともにさらなる改善を進めていく予定です。皆さんもぜひ、今回の実装例を参考にして、サイトのSEO対策にチャレンジしてみてください。
参考資料
さらに詳しく知りたい場合はこちら